There are a lot of ways to make the software you write vulnerable (if you’re a developer) or to exploit existing software (if you’re on the other side). In this post I’ll be talking about buffer overflows.
A buffer overflow is a bug in software where memory gets overwritten due to a buffer being assigned a value that is bigger than the buffer’s size.
How?
Let’s take a look at a little example written in C.
#include <stdio.h>
int main()
{
char buff[6];
char a = 'A';
printf("Var a: %c\n", a);
printf("Enter buff: ");
scanf("%s", buff);
printf("Value of buff: %s\n", buff);
printf("Value of a: %c\n", a);
}
Overflow.c
The example is really simple. A char array (buff) with size 6 is allocated*, and a char (a) which has the value of ‘A’. If you remember from my last post, chars are stored as single bytes. After that, the program asks for an input from the user. Then, it prints the value of the 2 declared variables.
*If you don’t know, variables are allocated in a “stack” in memory in the order that they were declared.
Let’s compile the example with GCC 8.3 and run it: gcc -fno-stack-protector -o overflow Overflow.c
I’ll explain the compilation part in the end. For now, let’s just run it: ./overflow
Example 1
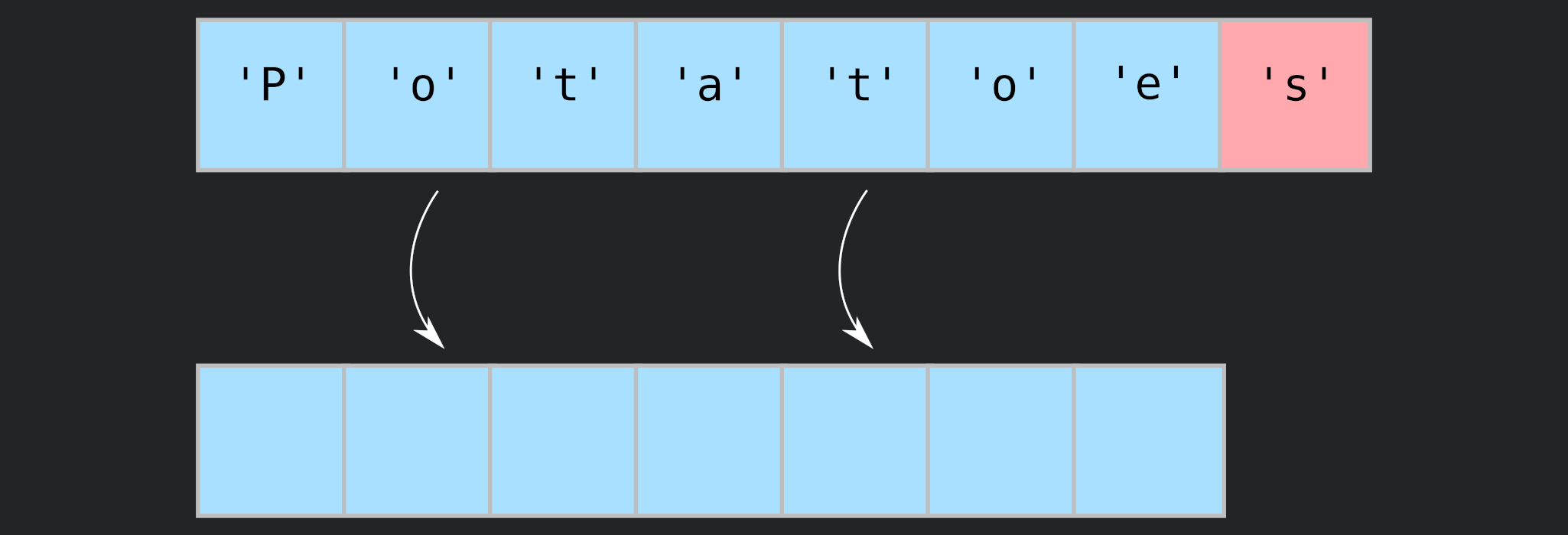
The stack of the main function initially looks something like this:

Excuse the horizontal stack, stacks are a social construct anyway.
The char a has been assigned the value ‘A’, and the chars in the “buff” array are initialised to NULL.
When taking the input for “buff” (line 12), we give it an input of “Three”:
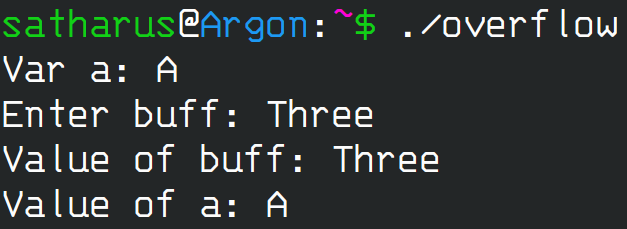
Example 1
The program behaves normally. Here’s what the stack looks like:

Each character is placed into its place in the char array, and a final NULL terminator is added. Seems good so far.
Example 2
Let’s try another input, let’s try something that’s 6 characters in length, like the word “potato”.
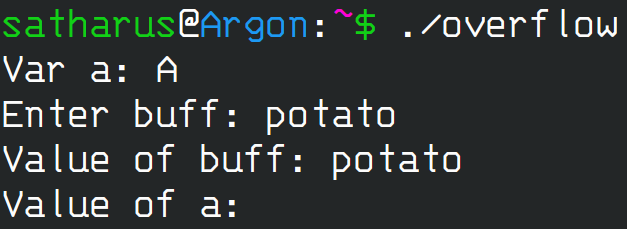
Example 2
There’s a change in the program’s behaviour! The value of the char a wasn’t printed. This is where our first buffer overflow happens.

Like example 1, each character is placed into its place in the char array, and a final NULL terminator is added. But this time since “potato” has six characters and our array (buff) can only hold 6 characters, the NULL terminator was written into character a’s location in memory. The truth is that the value of a was printed, but since the value is NULL, we didn’t get any visible/printable output for it.
Example 3
Let’s try one final input, and see how the program behaves.
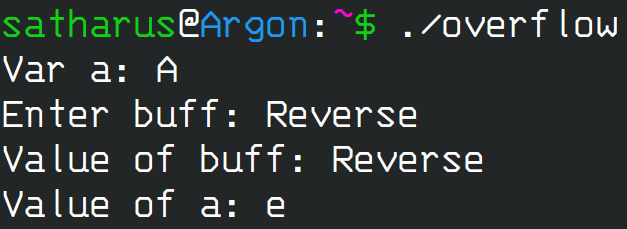
Example 3
Again, we see a change in behaviour. This time, the value of a is printed, but it isn’t ‘A’.
This is also a buffer overflow, but since “Reverse” contains 7 characters, the NULL terminator was written after a’s location in memory. The value ‘e’ was written in a’s location in memory.

Okay, now what?
Buffer overflows happen a lot, especially with new developers and developers that aren’t aware that such vulnerabilities can exist.
I may talk about exploiting buffer overflows in another post later on. But for now, you know that they exist.
How can I prevent buffer overflows?
There are a lot of methods you can protect your program with, the simplest one of them all is checking for user input carefully before letting it into your program. As they say, user input is the root of all vulnerabilities.
I didn’t add any checking or protection in the example above since, well, I wanted to show you live examples of buffer overflows.
Good news, though. A lot of modern compilers enable stack protection by default, where they don’t allow most buffer overflows to happen by returning a segmentation fault if the stack is changed in a strange manner.
Now to explain the compilation part, remember the -fno-stack-protector option that was added to the GCC compilation? That was to disable stack protection so that the buffer overflow would work. If I were to remove that option, and compile it with just: gcc -o overflow Overflow.c the program would return a segmentation fault whenever any buffer overflows happened.
You can learn more about stack protection, here.
Here’s a post showing an actual buffer overflow exploit in a CTF challenge. Give it a read, now that you know what a buffer overflow is.
Thanks a lot for reading this post. I hope you enjoyed it and learnt something new! Share it with your friends if you think they’ll find it interesting. I’ll appreciate any questions or feedback!